循序漸進,涉及面廣
站在初學者的角度,循序漸進地介紹使用Python開發網路爬蟲的各
種知識,內容由淺入深,涵蓋目前網路爬蟲開發的各種熱門工具和前瞻性技術。
從理論到實作,培養爬蟲開發思維
在說明過程中,不僅介紹理論知識,注重培養讀者的爬蟲開發思維,而且安排綜合應用實例或小型應用程式,讓讀者能順利地將理論應用到實作中。
實戰專案豐富,擴充性強
作者精心設計和挑選,根據實際開發經驗歸納而來的實戰專案,涵蓋在實際開發中所遇到的各種問題。說明步驟詳盡、結構清晰、分析深入淺出,而且案例擴充性強,讓讀者更容易掌握爬蟲開發技術,以應對業務需求,還可根據實際需求擴充開發。
內容豐富,傾情分享
本書內容都來自作者多年的程式設計實作,操作性很強。還介紹爬蟲軟體和爬蟲架構的開發,幫助讀者擴充知識結構,提升開發技能。
適合讀者群:Python網路爬蟲初學者、Python初級爬蟲工程師、從事資料抓取和分析的技術人員,或學習Python程式設計的開發人員。
本書特色
一本讓你夠格去Google、百度、微軟、fb上班的修鍊大法
◎爬文字、爬評論、爬音樂、爬圖片、爬電影,無所不爬!
◎存文字、存表格、存word、存db,存json、存csv,什麼都存!
◎Fiddler、 urlib、 requests、 selenium、 appium、 scrapy,樣樣都有!
◎SQLAchemy、 MongoDB、MySQL、Redis、 SQLServer,格式通吃!
◎百度、QQ、微博、求職網、搶票網、購物網、房仲網,通通都抓!
◎自己完成爬蟲視窗程式、自己開發爬蟲架構、自己設計反爬機制!
作者簡介:
黃永祥
CSDN博客專家和簽約講師,多年軟體研發經驗,主要從事機器人流程系統、大數據系統、網路爬蟲研發,以及自動化運維系統研發。擅長使用Python編寫高品質程式碼,對Python有深入研究,熱愛分享和新技術的探索。
作者序
前言
隨著大數據和人工智慧的普及,Python 的地位也變得水漲船高,許多技術人員投身於Python 開發,其中網路爬蟲是Python 最為熱門的應用領域之一。在爬蟲領域,Python 可以說是處於霸主地位,Python 能解決爬蟲開發過程中所遇到的難題,開發速度快且支援非同步程式設計,大幅縮短了開發週期。此外,從事資料分析的工程師,為取得資料,很多時候也會用到網路爬蟲的相關技術,因此,Python 爬蟲程式設計已成為爬蟲工程師和資料分析師的必備技能。
✤ 本書結構
全書分28 章,各章內容概述如下:
第1 章介紹什麼是網路爬蟲、爬蟲的類型和原理、爬蟲搜索策略和爬蟲的合法性及開發流程。
第2 章說明爬蟲開發的基礎知識,包含HTTP 協定、請求標頭和Cookies 的作用、HTML 的版面配置結構、JavaScript 的介紹、JSON 的資料格式和Ajax 的原理。
第3 章介紹使用Chrome 開發工具分析爬取網站, 重點介紹開發工具的Elements 和Network 標籤的功能和使用方式,並透過開發工具分析QQ 網站。
第4 章主要介紹Fiddler 封包截取工具的原理和安裝設定,Fiddler 使用者介面的各個功能及使用方法。
第5 章說明Urllib 在Python 2 和Python 3 的變化及使用,包含發送請求、使用代理IP、Cookies 的讀寫、HTTP 憑證驗收和資料處理。
第6 ~ 8 章介紹Python 協力廠商函數庫Requests、Requests-Cache 爬蟲快取和Requests-HTML,包含發送請求、使用代理IP、Cookies 的讀寫、HTTP 憑證驗收和檔案下載與上傳、複雜的請求方式、快取的儲存機制、資料清洗以及Ajax 動態資料爬取等內容。
第9 章介紹網頁操控和資料爬取,重點說明Selenium 的安裝與使用,並透過實戰專案「百度自動答題」,說明Selenium 的使用。
第10 章介紹手機App 資料爬取,包含Appium 的原理與開發環境架設、連接Android 系統,並透過實戰專案「淘寶商品擷取」,介紹App 資料的爬取技巧。
第11 章介紹Splash、Mitmproxy 與Aiohttp 的安裝和使用,包含Splash 動態資料抓取、Mitmproxy 封包截取和Aiohttp 高平行處理抓取。
第12 章介紹驗證碼的種類和識別方法,包含OCR 的安裝和使用、驗證碼圖片處理和使用協力廠商平台識別驗證碼。
第13 章說明資料清洗的三種方法,包含字串操作(截取、尋找、分割和取代)、正規表示法的使用和協力廠商函數庫BeautifulSoup 的安裝以及使用。
第14 章說明如何將資料儲存到檔案,包含CSV、Excel 和Word 檔案的讀取和寫入方法。
第15 章介紹ORM 架構SQLAlchemy 的安裝及使用,實現關聯式資料庫持久化儲存資料。
第16 章說明非關聯式資料庫MongoDB 的操作,包含MongoDB 的安裝、原理和Python 實現MongoDB 的讀寫。
第17 ~ 21 章介紹5 個實戰專案,分別是:爬取51Job 應徵資訊、分散式爬蟲——QQ 音樂、12306 搶票爬蟲、微博爬取和微博爬蟲軟體的開發。
第22 章至第25 章介紹Scrapy 爬蟲架構,包含Scrapy 的執行機制、專案建立、各個元件的撰寫(Setting、Items、Item Pipelines、Spider)和檔案下載及Scrapy 中介軟體,並透過實戰專案「Scrapy+Selenium 爬取豆瓣電影評論」、「Scrapy+Splash 爬取B 站動漫資訊」和「Scrapy+Redis 分散式爬取貓眼排行榜」、「爬取鏈家房地產資訊」和「QQ 音樂全站爬取」,深入說明了Scrapy的應用和分散式爬蟲的撰寫技巧。
第26 章介紹爬蟲的上線部署,包含非架構式爬蟲和架構式爬蟲的部署技巧。
第27 章介紹常見的反爬蟲技術,並列出可行的反爬蟲解決方案。
第28 章介紹爬蟲架構的撰寫,學習如何自己動手撰寫一款爬蟲架構,以滿足特定業務場景的需求。
✤ 本書特色
循序漸進,有關面廣:本書站在初學者的角度,循序漸進地介紹使用Python 開發網路爬蟲的各種知識,內容由淺入深,幾乎涵蓋了目前網路爬蟲開發的各種熱門工具和前瞻性技術。
實戰專案豐富,擴充性強:本書採用大量的實戰專案說明,力求透過實際應用讓讀者更容易地掌握爬蟲開發技術,以應對業務需求。本書專案經過編者精心設計和挑選,根據實際開發經驗歸納而來,涵蓋了在實際開發中所遇到的各種問題。對於精選專案,盡可能做到步驟詳盡、結構清晰、分析深入淺出,而且案例的擴充性強,讀者可根據實際需求擴充開發。
從理論到實作,注重培養爬蟲開發思維:在說明過程中,不僅介紹理論知識,注重培養讀者的爬蟲開發思維,而且安排了綜合應用實例或小型應用程式,讓讀者能順利地將理論應用到實作中。
內容豐富,傾情分享:本書大部分內容都來自作者多年來的程式設計實作,操作性很強。值得關注的是,本書還介紹了爬蟲軟體和爬蟲架構的開發,供學有餘力的讀者擴充知識結構,提升開發技能。
✤ 繁體中文版說明
本書原作者為中國大陸人士,書中範例多為簡體中文網頁,為求全書內容完整,文中例圖多為簡體中文顯示,請讀者對照前後文閱讀。
✤ 原始程式碼下載
本書所有程式碼均在Python 3.6 下偵錯通過,原始程式碼Github 下載網址:https://github.com/xyjw/python-Reptile
如果在下載過程中遇到問題,可發送郵件至554301449@qq.com 獲得幫助,郵件標題為「實戰Python 網路爬蟲下載資源」。
✤ 技術服務
讀者在學習或工作的過程中,如果遇到實際問題,可以加入QQ 群93314951與筆者聯繫,筆者會在第一時間給予回覆。
✤ 適合讀者群
本書主要適合以下讀者閱讀:
■ Python 網路爬蟲初學者及在校學生。
■ Python 初級爬蟲工程師。
■ 從事資料抓取和分析的技術人員。
■ 學習 Python 程式設計的開發人員。
雖然筆者力求本書更臻完美,但由於功力所限,難免會出現錯誤,特別是實例中爬取的網站可能隨時更新,導致原始程式在執行過程中出現問題,歡迎讀者們和高手專家給予指正,筆者將十分感謝。
黃永祥
前言
隨著大數據和人工智慧的普及,Python 的地位也變得水漲船高,許多技術人員投身於Python 開發,其中網路爬蟲是Python 最為熱門的應用領域之一。在爬蟲領域,Python 可以說是處於霸主地位,Python 能解決爬蟲開發過程中所遇到的難題,開發速度快且支援非同步程式設計,大幅縮短了開發週期。此外,從事資料分析的工程師,為取得資料,很多時候也會用到網路爬蟲的相關技術,因此,Python 爬蟲程式設計已成為爬蟲工程師和資料分析師的必備技能。
✤ 本書結構
全書分28 章,各章內容概述如下:
第1 章介紹什麼是網路爬蟲、爬蟲的類型和原...
目錄
前言
01了解網路爬蟲
1.1 爬蟲的定義
1.2 爬蟲的類型
1.3 爬蟲的原理
1.4 爬蟲的搜索策略
1.5 爬蟲的合法性與開發流程
1.6 本章小結
02 爬蟲開發基礎
2.1 HTTP 與HTTPS
2.2 請求標頭
2.3 Cookies
2.4 HTML
2.5 JavaScript
2.6 JSON
2.7 Ajax
2.8 本章小結
03 Chrome 分析網站
3.1 Chrome 開發工具
3.2 Elements 標籤
3.3 Network 標籤
3.4 分析QQ 音樂
3.5 本章小結
04 Fiddler 封包截取
4.1 Fiddler 介紹
4.2 Fiddler 安裝設定
4.3 Fiddler 抓取手機應用
4.4 Toolbar 工具列
4.5 Web Session 列表
4.6 View 選項視圖
4.7 Quickexec 命令列
4.8 本章小結
05 爬蟲函數庫Urllib
5.1 Urllib 簡介
5.2 發送請求
5.3 複雜的請求
5.4 代理IP
5.5 使用Cookies
5.6 證書驗證
5.7 資料處理
5.8 本章小結
06 爬蟲函數庫Requests
6.1 Requests 簡介及安裝
6.2 請求方式
6.3 複雜的請求方式
6.4 下載與上傳
6.5 本章小結
07 Requests-Cache爬蟲快取
7.1 簡介及安裝
7.2 在Requests 中使用快取
7.3 快取的儲存機制
7.4 本章小結
08 爬蟲函數庫Requests-HTML
8.1 簡介及安裝
8.2 請求方式
8.3 資料清洗
8.4 Ajax 動態資料抓取
8.5 本章小結
09 網頁操控與資料爬取
9.1 了解Selenium
9.2 安裝Selenium
9.3 網頁元素定位
9.4 網頁元素操控
9.5 常用功能
9.6 實戰:百度自動答題
9.7 本章小結
10 手機App 資料爬取
10.1 Appium 簡介及原理
10.2 架設開發環境
10.3 連接Android 系統
10.4 App 的元素定位
10.5 App 的元素操控
10.6 實戰:淘寶商品擷取
10.7 本章小結
11 Splash、Mitmproxy與Aiohttp
11.1 Splash 動態資料抓取
11.2 Mitmproxy 封包截取
11.3 Aiohttp 高平行處理抓取
11.4 本章小結
12 驗證碼識別
12.1 驗證碼的類型
12.2 OCR 技術
12.3 協力廠商平台
12.4 本章小結
13 資料清洗
13.1 字串操作
13.2 正規表示法
13.3 BeautifulSoup 資料清洗
13.4 本章小結
14 文件資料儲存
14.1 CSV 資料的寫入和讀取
14.2 Excel 資料的寫入和讀取
14.3 Word 資料的寫入和讀取
14.4 本章小結
15 ORM 架構
15.1 SQLAlchemy 介紹與安裝
15.2 連接資料庫
15.3 建立資料表
15.4 新增資料
15.5 更新資料
15.6 查詢資料
15.7 本章小結
16 MongoDB 資料庫操作
16.1 MongoDB 介紹
16.2 MogoDB 的安裝及使用
16.3 連接MongoDB 資料庫
16.4 新增文件
16.5 更新文件
16.6 查詢文件
16.7 本章小結
17 實戰:爬取51Job應徵資訊
17.1 專案分析
17.2 取得城市編號
17.3 取得應徵職務總頁數
17.4 爬取每個職務資訊
17.5 資料儲存
17.6 爬蟲設定檔
17.7 本章小結
18 實戰:分散式爬蟲--QQ 音樂
18.1 專案分析
18.2 歌曲下載
18.3 歌手的歌曲資訊
18.4 分類歌手列表
18.5 全站歌手列表
18.6 資料儲存
18.7 分散式爬蟲
18.8 本章小結
19 實戰:12306 搶票爬蟲
19.1 專案分析
19.2 驗證碼驗證
19.3 使用者登入與驗證
19.4 查詢車次
19.5 預訂車票
19.6 提交訂單
19.7 生成訂單
19.8 本章小結
20 實戰:玩轉微博
20.1 專案分析
20.2 使用者登入
20.3 使用者登入(帶驗證碼)
20.4 關鍵字搜索熱門微博
20.5 發布微博
20.6 關注使用者
20.7 按讚和轉發評論
20.8 本章小結
21 實戰:微博爬蟲軟體開發
21.1 GUI 函數庫及PyQt5 的安裝與設定
21.2 專案分析
21.3 軟體主介面
21.4 相關服務介面
21.5 微博擷取介面
21.6 微博發佈介面
21.7 微博爬蟲功能
21.8 本章小結
22 Scrapy 爬蟲開發
22.1 認識與安裝Scrapy
22.2 Scrapy 爬蟲開發範例
22.3 Spider 的撰寫
22.4 Items 的撰寫
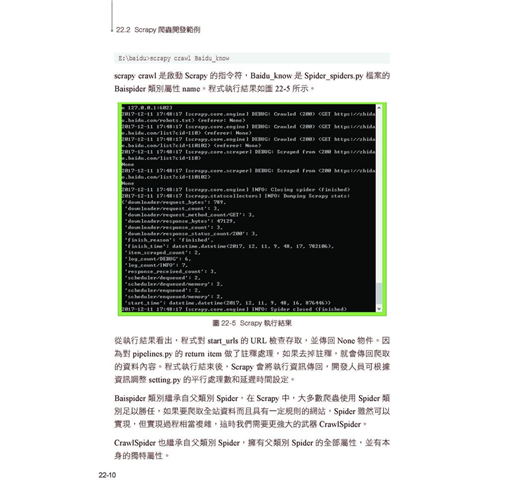
22.5 Item Pipeline 的撰寫
22.6 Selectors 的撰寫
22.7 檔案下載
22.8 本章小結
23 Scrapy 擴充開發
23.1 剖析Scrapy 中介軟體
23.2 自訂中介軟體
23.3 實戰:Scrapy+Selenium 爬取豆瓣電影評
23.4 實戰:Scrapy+Splash 爬取B 站動漫資訊
23.5 實戰:Scrapy+Redis 分散式爬取貓眼排行榜
23.6 分散式爬蟲與增量式爬蟲
23.7 本章小結
24 實戰:爬取鏈家房地產資訊
24.1 專案分析
24.2 建立專案
24.3 專案設定
24.4 定義儲存欄位
24.5 定義管線類別
24.6 撰寫爬蟲規則
24.7 本章小結
25 實戰:QQ 音樂全站爬取
25.1 專案分析
25.2 專案建立與設定
25.3 定義儲存欄位和管線類別
25.4 撰寫爬蟲規則
25.5 本章小結
26 爬蟲的上線部署
26.1 非架構式爬蟲部署
26.2 架構式爬蟲部署
26.3 本章小結
27 反爬蟲的解決方案
27.1 常見的反爬蟲技術
27.2 以驗證碼為基礎的反爬蟲
27.3 以請求參數為基礎的反爬蟲
27.4 以請求標頭為基礎的反爬蟲
27.5 以Cookies 為基礎的反爬蟲
27.6 本章小結
28 自己動手開發爬蟲架構
28.1 架構設計說明
28.2 非同步爬取方式
28.3 資料清洗機制
28.4 資料儲存機制
28.5 實戰:用自製架構爬取豆瓣電影
28.6 本章小結
前言
01了解網路爬蟲
1.1 爬蟲的定義
1.2 爬蟲的類型
1.3 爬蟲的原理
1.4 爬蟲的搜索策略
1.5 爬蟲的合法性與開發流程
1.6 本章小結
02 爬蟲開發基礎
2.1 HTTP 與HTTPS
2.2 請求標頭
2.3 Cookies
2.4 HTML
2.5 JavaScript
2.6 JSON
2.7 Ajax
2.8 本章小結
03 Chrome 分析網站
3.1 Chrome 開發工具
3.2 Elements 標籤
3.3 Network 標籤
3.4 分析QQ 音樂
3.5 本章小結
04 Fiddler 封包截取
4.1 Fiddler 介紹
4.2 Fiddler 安裝設定
4.3 Fiddler 抓取手機應用
4.4 Toolbar 工具列
4.5 Web Ses...
商品資料
出版社:深智數位股份有限公司出版日期:2020-04-22ISBN/ISSN:9789865501273 語言:繁體中文For input string: ""
裝訂方式:平裝頁數:624頁
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。


 收藏
收藏

 3二手徵求有驚喜
3二手徵求有驚喜